
The HPA Tech Retreat is an annual gathering in the desert east of Los Angeles (in a posh resort, mind you; it’s not like we’re out sitting in the hot sun among the Joshua trees) where film and TV industry folks discuss all manner of technical and business issues. There are two parallel Monday sessions, an ATSC meeting and a tech talk; I attended the tech talk. Charles Poynton and John Watkinson discussed Physics, Psychophysics, and Vision for Advanced Motion Imaging.


Charles Poynton & John Watkinson
I took notes, which I reproduce here. CP is Charles Poynton, JW is John Watkinson. My comments are in [square brackets]and any errors therein are mine alone.
Note: if the presentation seems both somewhat (a) geeky and (b) scattershot, that’s because it was.
CP: 4K is going to happen anyway, so why are we here? Perhaps we might learn some thing about how and why.
JW: If we’re going to change anything we have to understand it. You have to have a model for how something works. Until recently we didn’t have a model for moving pictures. Now we do: the model for the human visual system and how it interacts with displays. Once you understand that, you can see why many things that have been done, have been done – and why certain other things don’t work so well.
CP: Our first topic is eye tracking. You can model an image as a distribution of frequencies across X and Y, we sample that at discrete elements (e.g., the square pixel). This turns out to be wrong: we don’t want to sample with a squared-off function, but some other function peaking at the “pixel” location but with a different spatial distribution. Extending Shannon’s 1D sampling theory to 2D is simple enough; extending to 3D may not be as simple, but if you try, you have X, Y and T (time); that’s completely wrong: sampling theory doesn’t apply to the temporal axis.
Video vs film sampling: video cameras originally scanned top-to-bottom, the sample was skewed [rolling shutter], so if you were to scan film to video via “dual port” memory accesses, you’ll get tears where the 2-3 pulldown causes memory pointer crossings. Put another way, as something moving across the film frame is scanned, you’ll get a sequence of frames; your eye will track it (“smooth pursuit”) as opposed to a saccade ([a jump in the focal point of the gaze]: effectively the optical nerve turns off, the eye moves, the eye turns back on, which is why you don’t see a blur during a saccade). Consider an ”EAT AT JOES” LED sign. If the sign is refreshed from top to bottom, and your eye tracks past it, the sign will appear as italics. If you try to boost the luminous efficiency of the sign by refreshing the top and the bottom halves separately, you’ll get a tearing mid-line; if you drive from top and bottom, you’ll get a fold.




For classical film, 24fps, but 50% exposure duty cycle, so 1/48 sec exposure. A vidicon (or other tube) has continuous integration during the 1/60 sec field. A CCD has a variable integration window. Film projectors double-flash; this causes a judder on motion from the eye’s smooth pursuit. CRT persistence on the order of 50 microsecond; the “pixel” is on for 1/500 of the frame time. The image goes POW! and your eyes pick up on it, but keep tracking during the dark rest of the frame. When the next frame (or field) goes POW! your eye is in the right place for it to appear. LCDs stay on, so when the image appears and your eye tracks across it, the image smears for the entire duration of the frame. A 16-pixel ping-pong ball crossing an HD screen in 1 second crosses 32 pixels per frame; it’ll look 48 pixels wide when you track it on an LCD.

JW: The bad news is that a lot of what were doing today doesn’t work. Boosting static resolution in moving pictures is a waste of time: it’s like rating a Lamborghini by testing the parking brake! (John pulls out an overhead projector, saying it’s the only actual moving picture device around: everything else just shows a series of stills. He moves the slide on the stage, and that’s it: the only truly “moving picture” we’ll see!) Motion imaging is a multifaceted topic, not something you can solve quickly. We only call them “moving pictures” to deceive the public. We don’t have high definition TV, just the same old problems with more problems. We are in great danger of “improving” TV by throwing more pixels at it.

What I plan to do is creep up on the topic of motion by looking at sampling, then sampling things that move. Moving pix are samples in height, width, and time, and that’s it, right? Wrong: you can’t describe the HVS (human visual system) that way.
The temporal response of the eye is poor: response drops dramatically as frequency increases; around 50 Hz (give or take) is pretty much drops off to zero (CP points out that the eye responds faster in brighter light, slower in lower light). Spatial detail moving past the eye’s gaze point results in temporal frequencies. Moving things often go fast enough for fine detail to exceed a 50 Hz rate, but the eye’s smooth pursuit (instead of having a fixed gaze) allows items of interest to be fixed in the gaze; it becomes static as far as the eye is concerned. That’s the fundamental concept: if you don’t understand that, leave now! When the eye is tracking a subject, the temporal frequencies in that subject drop to zero.
When you shoot the same scene with a camera, then try to track the subject in the reproduced scene, you don’t get the same sharpness: motion blur during capture and display erases the detail: the temporal frequencies present in the scene were not removed (temporal aperture effect). Indeed, much of the language of cinematography involves following subjects of interest to avoid motion blur. What to measure: static resolution isn’t useful; we need dynamic resolution: the resolution perceived by a tracking eye. For example, after a cut, the eye is busy finding something to look at. Only after it locks on and starts tracking something does dynamic resolution matter.
Sampling is used extensively in audio and video; the problem is that it’s only done right in audio (sometimes it can’t be done right in video; light isn’t sound). A sampled system has to contain LPFs (low pass filters) to prevent aliasing.
We know that all sampled systems must be followed by a reconstruction process. We don’t hear separate samples on a CD, but we see samples all the time on TV and film: the reconstruction isn’t being done. If it had been, you wouldn’t see frames, you wouldn’t see a raster on a CRT. The ideal impulse response for electrical signals is a unity impulse, dropping suddenly to zero. The LPF of this is a sinc filter; this has negative-going lobes; hard to do with light, which can’t go negative the way an electrical signal does. The best you can do is ignore those negative lobes, but even the best you can do is better than doing nothing.
Ideal Shannon sampling is sampling at an infinitely small point. If samples are infinitely narrow, frequency response is flat up to FS/2. If samples are wider, you’re convolving with a rectangle; this rolls off higher frequencies (wider pixels are the same, really as motion blur). When the aperture ratio is 100%, response is 0.64 at FS/2 [half the sampling frequency](this corresponds to a sensor with 100% fill factor; they have the worst aperture effect that can be achieved!). The same sort of thing happens on displays; large fill-factor displays have similar aperture effects. If a camera or display is 4dB down (0.64x) at FS/2, camera+display is 8dB down… even if nothing moves.
Thus an N-line sensor cannot have N lines of resolution. However, an N-line pixel array (in memory) can have N lines of resolution. Thus cameras and displays should have more lines of resolution than the transmission format (classical oversampling). This works so well in other applications, it’s a wonder it isn’t done more in TV and film.
We can’t make a brick-wall optical filter since we can’t do negative light. So if we have an aggressive AA (anti-alias) filter, we’ll have no aliasing, but no resolution either. But if you oversample the camera, that gives you more spatial room for filtering so you can capture more data with an aggressive AA filter tuned for the greater number of pixels, then brick-wall-filter digitally.
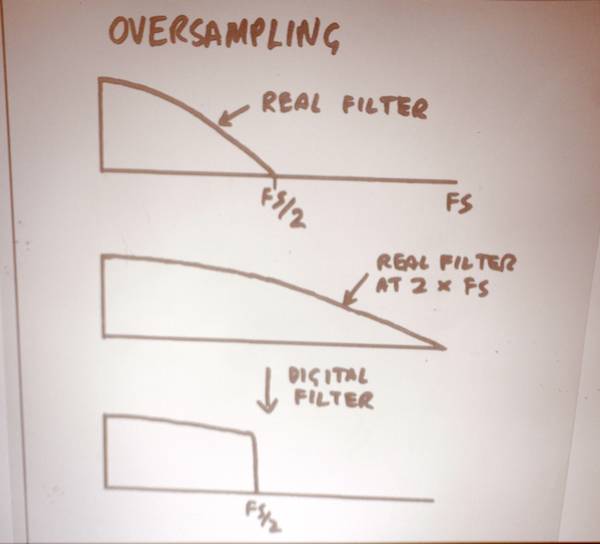
On the display side, interpolate to fill the larger raster.
Don’t get me wrong; no argument against 4K for cameras and displays, just no sense in transmitting 4K. The biggest problem in motion imaging isn’t resolution, it’s motion: inadequate frame rate. Trade off frame rate vs. static resolution for a constant pixel rate.
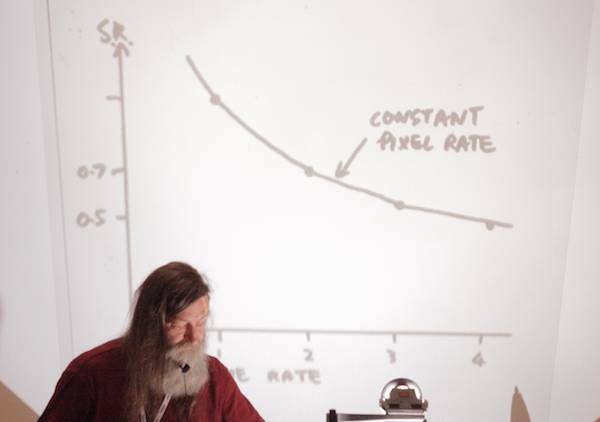
If you increase frame rate at expense of resolution, this aids MPEG compression (more redundancy), doesn’t necessarily increase the bit rate.
[side comment: There seems to be a threshold in frame rates where the brain work needed to fuse the motion goes down, around 75-100Hz.]CP: Strobing is all about the background: look up Poynton’s paper on the web: eye tracking, motion portrayal, and emerging display technology, 1996 <http://www.poynton.com/papers/Motion_portrayal/abstract.html>.


Discussion of PWM displays like DLP and plasma, and how the pulse train used to create a grayscale value will generate visual artifacts if your eye is tracking past it. Plasma has limits on how quickly cells can be switched [which limits bit depth], so they additionally dither values both spatially and temporally, which is why you’ll see some “noise” in plasma shadows. If a DLP switched in 10 microsec, than a DLP is a 100 kHZ frame rate display. A 10-bit 60 Hz display could also be a 9-bit 120 Hz display, etc. The D/A of a DLP is in your eye, on the “optical flow axis”.
John should have convinced you of the need for a presampling filter and a reconstruction filter, else you get aliases and jaggies and the like. To do really good motion portrayal on DLP, you need to be computing these 10 microsec 1-bit images to integrate properly on the optical flow axis: the place where the changes from frame to frame are at a minimum, e.g. following each individual’s eye tracking. We don’t really know how this optical integration works. We don’t even need frame rate: just provide information about the motion vectors (denser motion vectors than 16×16 MPEG). How do we get to the point where we encode and transmit these motion vectors?
There is no global frame clock on the retina; each sensor or bundle of sensors has its own triggering, and the higher the luminance, the faster the temporal response. The reason cinema gets away with 24fps is that cinema has an extremely sophisticated temporal filter: the cinematographer.
The brighter the picture, the greater the consumer acceptance.
The Sony BVM-E250 OLED displays use a 0.25 duty cycle (illuminated 25% of the time, dark 75% of the time) to get CRT-like sharpness with sufficient brightness, and not suffer smear like an LCD with a 100% duty cycle.
Poynton’s 5th law: if you do not disrupt your own business, somebody else will do it for you.
JW: The Optic Flow Axis: what is it? When an object is being tracked, the eye is looking up the optic flow axis, not the time axis. Along the optic flow axis, temporal frequency is zero. Compared to the fixed-in-view subject, the background is in a different place in each frame (as it moves behind the subject): background strobing.
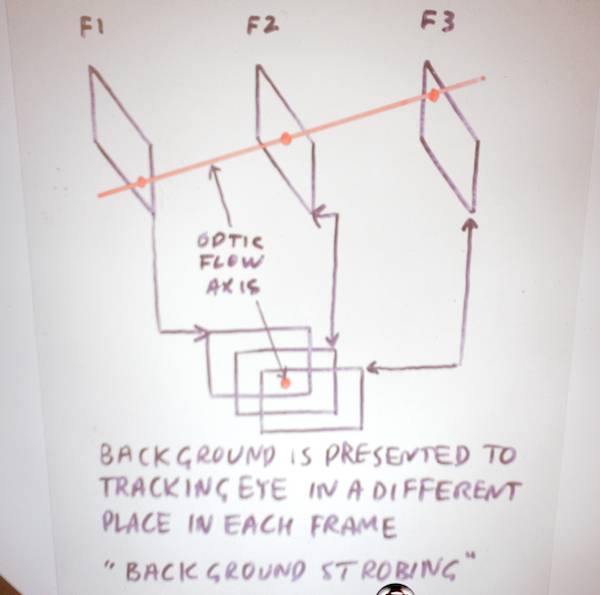
“One of the things about the human vision system is that you don’t see with it.” “Reality is an illusion brought on by a shortage of alcohol.”
One of the problems with 24Hz movies is that the frame rate is so low that the background moves in great lumps; soft focus needs to be used to soften it to make it acceptable. So what do we need more spatial resolution for movies? Traditional criterion: flicker suppression. Correct criterion: background strobing suppression.
The optical flow axis is not orthogonal to the screen; a temporal aperture on the OFA leads to a spatial aperture in the image plane: motion affect resolution. We all know that in still photography we want a short shutter speed for sharp motion. In motion, this translates to a high frame rate. Motion blur is another aperture effect. Fourier transform of a rectangle is sin x / x. (But the aperture may not be rectangular; Tessive time filter [now RED Motion Mount]uses a shaped, roughly sinusoidal aperture.) If we just use a short shutter speed in motion pictures it only points out the strobing from 24fps refreshing. Hence the use of slow, 1/48 shutters, and background defocusing via shallow focus. Before we can use short shutter times, we have to get rid of artifacts: you must go to high frame rates. Just throwing more pixels at it is stupid.
If you shoot 24fps, it’s OK; the problem comes on projection: at 24fps, half the audience will leave, half will have epileptic fits. The fix: double-shuttering at 48fps. But now we get double-flash judder: We never see the improvement in larger frame formats because the judder destroys perceived resolution; the dominant visual effect is double-imaging. If you don’t fix the dominant problem, you’re wasting your time.
This is where the grammar of cinematography comes from: big formats with big lenses and shallow depth of field to avoid background strobing. Ensure smooth camera motion: fluid heads, dollies on rails, etc. Avoid rapid motion, track moving things. Large temporal aperture: big shutter angle (180º) to defocus motion. It all adds up to “the film look”. If you like it, you can still get it even if you shoot HFR. It’s not necessary for the film look to change if you use better technology, you can stick with the old look – but you don’t have to stay with the film look if you don’t like it.
Even worse: 3:2 pulldown. Look what it does to the optic flow axis:
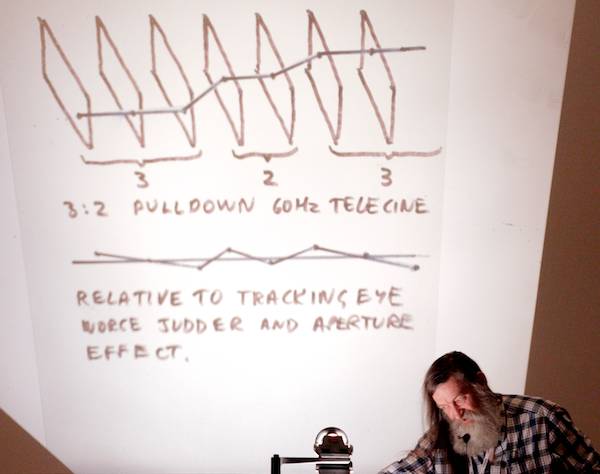
“Dallas” was shot on film, cut on film, telecined at 60Hs for the US and at 50Hz for Europe. Then some smart-ass (tech term) decided to save money by standards-converting the 60Hz video for Europe… once. The optic flow axis wasn’t damaged, it was vaporized! They went back to separate telecines after that.
Interlace: a form of cheating. You give people less, and tell ‘em they’re getting the full frame. It’s a merciless con. Interlace is technically called vertico-temporal quincunx sampling. Try saying that five times fast. Here’s what happens [JW holds two superimposed sheets over the projector, one above the other representing two fields. Aligned on the level, they represent a staid image; tilted, what happens with inter-field motion]:

Static interlaced fields

Interlaced fields with vertical motion.
“Interlace quite obviously doesn’t work.” What velocity does this occur at: when the vertical velocity is [any odd multiple of]one scanline per frame.
Interlace actually works better in NTSC than PAL, because the frame rate is higher even though the spatial resolution is lower. Interlace and HD go together like Robert Mugabe and human rights. Interlaced loss of resolution is higher in high def. Vertical resolution keeps varying between full and half depending on vertical motion.
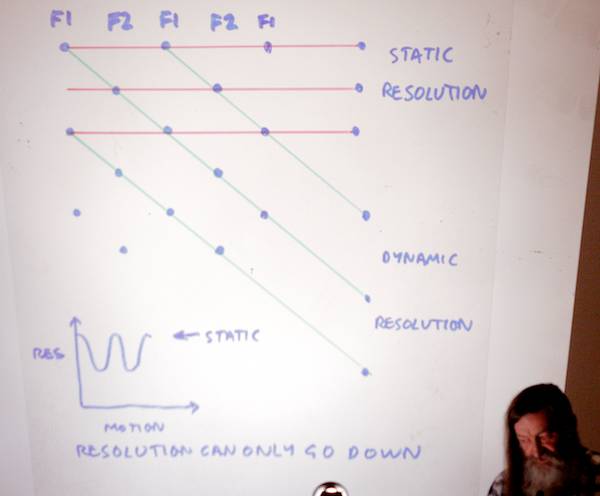
In progressive, inter-frame motion doesn’t cause loss of static resolution; it actually increases.

What happens with inter-frame motion: an apparent resolution increase.
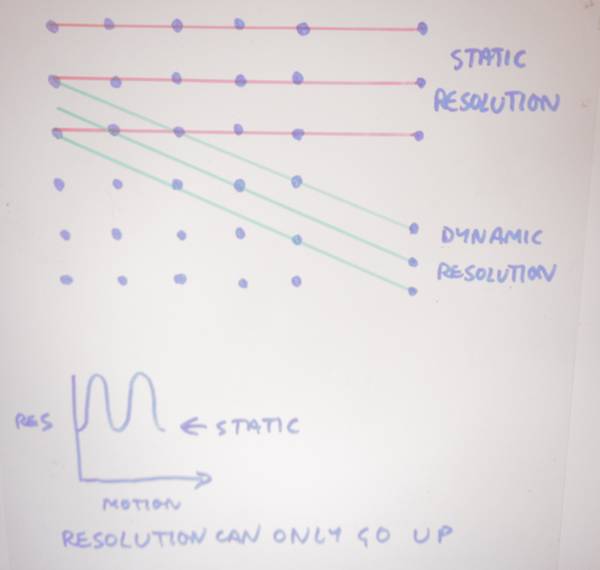
Interlace is not used in UHD TV. Good riddance, is all I can say.
Interlace problems: frame-rate flicker still visible; vertical-motion aliasing; vertical detail spread across two fields, making re-sizing complex; irrelevant for bandwidth reduction in MPEG systems; field difference could be vertical detail, or it could be motion, and this confuses motion estimators.
Interlaced cameras use vertical filtering [and/or dual-row readout] to reduce the inter-field flicker problem.
Hight frame rate progressive images have greatly improved dynamic resolution compared to legacy formats. We can use spatial oversampling, short shutter times. High pixel counts aren’t necessary in the transmission channel. Use high pixel counts in the camera / on the display to make Bayer artifacts / RGB triads / actual pixel boundaries invisible.
What frame rate should we use? The aperture effect that causes motion blur is a rectangle, just like a 100% aperture, 100% fill-factor CCD or CMOS sensor. Generally speaking static resolution greatly exceeds dynamic resolution. If you can trade off spatial res vs frame rates, you should be able to find an optimum setting where the two match:
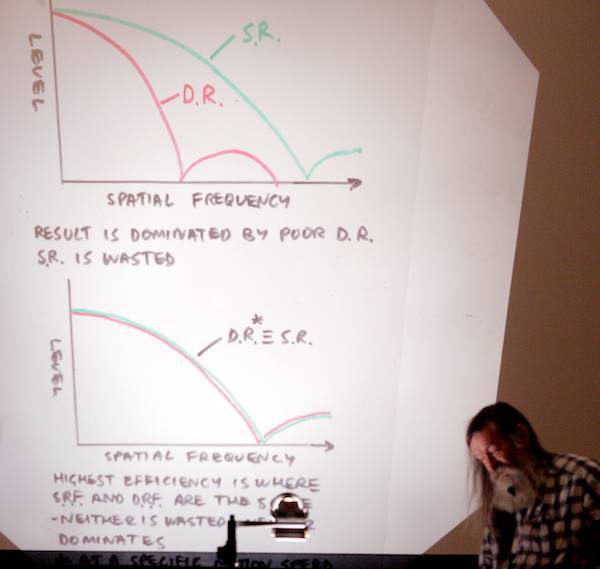
For a given type of material (fast-moving vs slower) you can figure out this optimum tradeoff. If you do the calculations, nowhere do you get 4K! You don’t even get 2K.
For high-res, HFR shooting (not 24fps or interlace): use large aperture to defocus the background; use short shutter speed (use NDs as needed for large apertures; use gain to allow short shutter times). Noise reduction works better with HFR due to inter-frame redundancies.
Can we test this? I use a 4K still camera, but I can’t hold it still enough (at typical film/video shutter speeds) without a tripod to get 4K of resolution out of it! So the theory is correct; I’ve tested it.
Question: How much of the frame is really moving such that you can’t appreciate the added resolution? HFR will give you sharper moving images but the stuff we shoot is typically stationary in the frame. Answer: resolution itself is only one parameter; improving it alone is meaningless. Regardless of resolution, background strobing is annoying; anything you do to fix that helps. HFR reduces background strobing, and it doesn’t prevent you from shooting “the old way”, too.
CP: Things we got right in ATSC DTV: square sampling; receivers must decode both interlace and progressive. Things we got wrong: forecasting the rate of improvement on DTV decoders; had we done it right, we’d have mandated that receivers must be able to decode 1080/60p, because by now MPEG-2 encoders can handle 1080/60p at ATSC data rates.
A fast tour of filtering / sampling / resampling math (this is all in the Orange Book [Poynton’s Digital Video and HDTV: Algorithms and Interfaces], so if you have it, there it is). The optimum sampling apertures usually have some negative excursions, but we have no negative light. So you can’t do an optimal job in the optical domain. Thus it’s almost always a good idea to oversample at the camera, downsample for transmission, then upsample at the display.
Light is from 400-700 nm (nanometers). Optimum way to sample light is three roughly gaussian, overlapping filters for R, G, B. The curves need to be tuned carefully, combining color science, engineering concerns, vision research, etc.
Consider a grid of pixels, equally spaced horizontally and vertically. The ideal sampling aperture is (roughly speaking) a Gaussian curve, with a strong response at the sampling point (a Gaussian curve is the convolution of an infinite series of rectangles). It’s the best you can do without negative light. If you can have those negative lobes, you get sin x / x.

Idealized bitmapped image, like Apple’s original 1-bit monochrome screen, only works if you’re locked to the pixel grid. It breaks on rotation, or on lateral [subpixel]motion. Proper presampling of images can be useful:


Poynton’s 4th law: sharpness is not always good; blurring isn’t always bad.
Why negative lobes on the filter make a difference (all this stuff is also in the Orange Book). Aliasing is a problem, even at FS/2: two signals with the same frequency (twice the sampling rate) but different phases and amplitudes, can sample to exactly the same numbers, as can other signals:
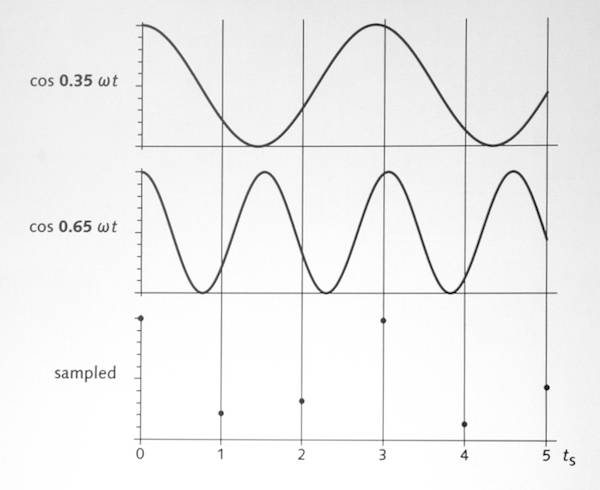
Frequencies getting close to the limits can lead to spurious data, too, especially using simple boxcar (square-windows) sampling.
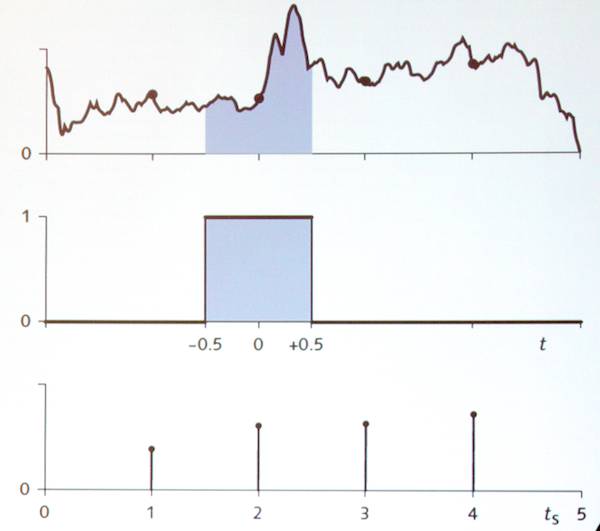
The frequency response of a boxcar sampling function is sin x / x (or sin pi*x / ( pi*x)) , a.k.a. sinc function.
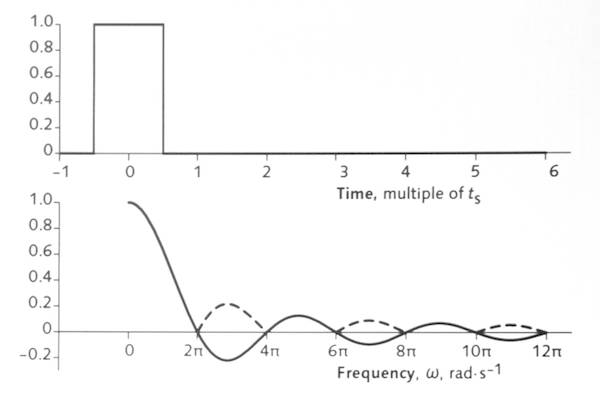
The Fourier transform of sinc is sinc. So if you want to make a resampling function (filter) that’s ideal in the sense of frequency response (like a brick-wall, unity to 0.5f, 0 thereafter). The weighting function to implement a boxcar (or brick-wall) is sinc, but optically you can’t get the negative lobes (negative light), and sin x / x is an infinite series; it never goes to zero (8 pixels to each side is a good approximation; 15 is really good). To get around the negative-light issue, oversample substantially in the camera, then implement sinc in filtering the digital signal, where you can have negative values quite easily. And that’s why 4K displays work: not that you see more detail, but that the display pixels are so invisibly small that they don’t contribute any visible aliasing by themselves.
A rant: take a 960×540 YouTube video and look at it on an iPhone (640×1136), it gets upsampled, and it looks really great (Apple really understands sampling: Google lyon apple filter design). Take a DVD and play it on a TV, it looks great, then put it on a MacBook: which looks better? I say it’s on the MacBook. Proper resampling, and no adaptive filters (edge detecting, contrast-boosting, etc. stuff that’s in the consumer TV guys’ DNA to do: the guys who made VHS look OK 20 years ago are nor the heads of signal processing at the TV builders: thus we get things like “fleshtone enhancement”!). I think the consumers are getting savvy, and content creators need to get savvy about how we deliver good pictures. 2K delivery for consumers is perfectly adequate, but 4K cameras and displays are definitely a good idea. So lets’s say that Samsung’s displays guy winds up lunching with Steven Spielberg and asking “how can we make your pictures look better?” Spielberg might reply, “Get your thumbs off my pixels! Don’t do any processing, just show what’s there!” It’s only in 2011 that we standardized 2.4 gamma at ITU! At SMPTE, standardizing Rec.709, we standardized camera gamma, but ignored display gamma, and it’s display gamma (mapping video inputs to display outputs) that counts. Display-referred counts more than scene-referred.
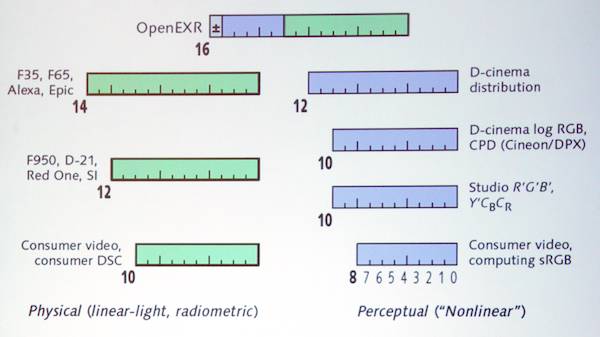
Bit depth: perceptually uniform coding is done using gamma functions. Gamma coding saves about two bits over linear coding. State of the art is to originate with 14-bit cameras, resulting in 12-bit perceptually encoded signals like D-Cinema. (In the graphic, green is linear, blue is perceptual coding; OpenEXR combines elements of both, with the exponent essentially “perceptual” and the mantissa being a linear 10 bits.)
JW: Gamma correction mathematically looks like a doubling of bandwidth, a recipe for aliasing. It only works for TV because TV’s resolution is so appallingly bad.
CP: We should consider the constant-luminance theorem for future TV standards. The only commercial deployment of wide gamut should use current SMPTE primaries and allow for negative numbers: turn off your clippers and limiters in image processing. Gamut legalizers should be outlawed (a rant for Friday!).
HPA Tech retreat 2014 full coverage: Day 1, Day 2, Day 3, Day 4, Day 5, wrap-up
Disclosure: HPA is letting me attend the conference on a press pass, but I’m paying for my travel, hotel, and meals out of my my own pocket. No company or individual mentioned in my coverage has offered any compensation or other material consideration for a write-up.
{kind=link}